提到資料庫特性勢必要先了解SQL(關聯式資料庫)vs.NoSQL(非關聯式資料庫)之間的差異,在應用的選擇上會帶來很大的幫助。
假設我們有以下內容,結構如下~
資料庫
Database :login (有多個會員紀錄相關資料表)
資料表
Table: user(會員資料),user_group(會員等級分類),user_type(會員所屬平台) 分別紀錄會員相關內容。
資料
Record: 會員siang的相關紀錄
| user_id (會員ID) | user_level(會員等級) |
|---|---|
| 1992132138111 | 1 |
| user_id (會員ID) | group_name (平台名稱) | group_id (平台ID) |
|---|---|---|
| 1992132138111 | iTHouse99 | 133122323123 |
user_id (會員ID) | user_name (會員名稱) | account (帳號) | password (密碼) | create_time (建立時間)
------------- | ------------- | ------------- | -------------
1992132138111 | siang | siang0056@gmail.com | 1234567 | 2021-07-27 12:23:02
在資料表設計上會根據不同作用功能(ex.會員登入註冊/商品內容/金流)資料去分成一至多個表存取相關內容,並在資料表之間設定彼此的關聯性。
在上面例子中當我需要一份完整的會員資料時,便可透過會員ID這個欄位的關聯性去連結其他表取得siang的所有欄位資料。
實務應用-在ACID的特性下,實務應用上著重於資料操作準確性與要求高度一致性。
ex.像是銀行系統或庫存系統一旦資料有誤差在後續處理是很麻煩的~
擴展性-縱向擴展,透過提升機器的硬體(ex.CPU/RAM/SSD)運算能力來平衡資料庫系統的負載。
SQL(Structured Query Language 結構化查詢語言)操作-透過SQL指令語言能在關聯式資料庫裡做到新增、修改、刪除資料的動作與建立及修改資料庫內容。
Not Only SQL代表不同於以往關聯式資料庫資料利用的方式,設計需求用來處理大量快速變化的非結構化資料。
開始前先複習一下關聯式資料庫的儲存資料方法 :
1.需事先定義好資料表的關係欄位。
2.儲存資料格式上需根據定義好的資料結構描述去新增對應值。
資料模型-分成多種不同屬性特點的模型。
ex.鍵值資料庫/文件資料庫/圖形資料庫/列式資料庫等...。 資料庫模型參考文件
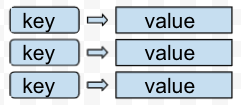
鍵值類型資料庫(Key-value Oriented Database)
每筆資料包含一組key(索引鍵)和value(資料內容),使用鍵值key-value對應關係存放資料,透過唯一索引鍵key(Primary key概念所以不會有重複值,同時也是效率好的原因)便可直接存取該key對應值。
儲存的資料格式:沒有限定結構內容,可以是(JSON,二進位資料,文字...)。
以後端來說常遇到有些資料的需求得頻繁的對資料存取更新,如果透過關聯式資料庫操作勢必會增加機器的負載量,而利用Nosql特性便可達到快速存取作用並且在寫入資料格式上也不會被侷限住。
ex. 常用的Redis(引用官方LOGO)
要注意Key-value儲存資料的方式,如果要修改現有紀錄值(value)的話,在執行上會覆寫掉原本的全部紀錄。看以下例子~
假設我要修改siang01的account值改成emp053@gmail.com。在記錄更動時只寫 {"account":"emp053@gmail.com"}
修改前:
| Key | Value |
|---|---|
| siang01 | {"user_id":"1992132138111","user_name":siang,"account":"siang0056@gmail.com"} |
修改後:
| Key | Value |
|---|---|
| siang01 | {"account":"emp053@gmail.com"} |
資料庫(儲存文件檔的集合) -> 集合(由多個文件所組成) -> 文件(資料內容)透過唯一索引鍵去找對應文件檔,鍵值對形式存儲。
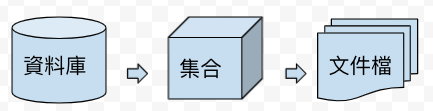
儲存的資料格式(value): XML or JSON格式儲存為文件檔。
| Key | Document |
|---|---|
| siang01 | {"user_id":1992132138111,"user_name":siang,"account":siang0056@gmail.com,"password": 1234567,"create_time": "2021-07-27 12:23:02"} |
SQL vs. NoSQL
相較於關聯式資料庫需表格化的預定義資料結構與關聯性。 NoSQL屬於動態結構,以鍵值對儲存,相對之下不侷限於固定的結構根據需要增加鍵值對,有效減少空間與時間的開銷。
上面只舉例幾個類型,針對nosql部分要了解每個不同類型DB資料儲存上的差異與著重特色參考Microsoft這篇文件在分類應用上寫的很詳細!推~
https://docs.microsoft.com/zh-tw/azure/architecture/data-guide/big-data/non-relational-data
SQL vs. NoSQL
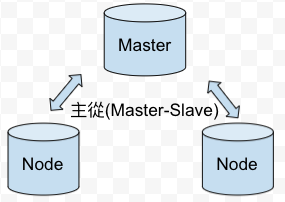
關聯式資料庫: 應用上由Master去負責全部資料的寫入請求,讀取的話轉由slave去分散master的負擔。
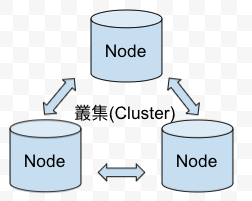
非關聯式資料庫: 在分散式架構下,每一個節點都等同於Master的概念,都能提供資料的讀寫請求。
ps.可以發現關聯式ACID與非關聯式CAP都有A和C,不過意義是完全不同的!
最終一致性:
代表在分散式系統架構下,所有對資料的更新操作最終都會反應在所有節點副本(每一台機器)上,但重要的是需要一些時間,最後資料副本會趨漸於一致。
那我們要知道在一個分散式的資料儲存架構下,不可能同時滿足以下三個條件,所以勢必得做出取捨~看以下例子
CA (犧牲分區容錯性)分散式的架構下基本上不會選擇,違反了設計初衷。
CP (犧牲可用性)分散式的架構下,資料會保證是一致性的,但相對的如果有節點異常失效造成資料尚未同步完整,會導致資料異常。(EX: 訊息類系統)
AP (犧牲一致性)分散式的架構下,用犧牲一致性換取系統高可用性,雖然在回傳資料上可能回傳不正確,但系統是保證可用的。在最後仍可以達到最終一致性只是相對的需要點時間去同步內容!!(EX:直播按讚功能,如果在同一時間有大量人數按讚,在每個人即時看到的按讚人數上可能會不同。隨著人數遞減,經過一點時間後在去看按讚統計人數是會達成一致的)
實務上三者中只能保證其中2個條件,無法達到同時符合一致性&可用性&分區容錯性的完美需求。
(ex.就像如果需要較高的一致性,那在分區容錯性上可能較差,除非你在可用性上讓步。)
應用選擇上
(資料多寡)
nosql優點就是在大數據時的效能,但如果你的資料量沒有達到一定的量,在效能上還是可能會比關聯式資料庫差。
(語法使用)
因為結構上的設計,nosql沒辦法像關聯式資料庫那樣使用join語法去查詢資料。
(資料格式)
如果在應用上變動幅度小且有明確的資料格式則選關聯式資料庫。
(資料應用)
資料要求準確性高不能出錯選關聯式資料庫,而資料使用頻繁度很高且結構不固定選非關聯式資料庫。
透過幾個重點像是ACID/CAP或資料存取架構,可以看到SQL與NOSQL之間的不同之處,在實際應用上還是取決於需求層面的變化。
下集預告: 萬事起頭需先把環境設置好,帶點輕鬆的資料庫安裝與環境部署~